Lizeo Research & Development
Machine learning and data science are at the heart of our R&D policy
AI at Lizeo
Since its creation, Lizeo has invested heavily in research and development applied to the massive data we collect every day.
We have naturally developed numerous machine learning algorithms. Most of them are the concrete implementation of scientific publications that we are presenting at various national and international conferences following in-house work or theses.
{kind=link}
{kind=link}
{kind=link}
- A thesis on anomaly detection presented in March 2018
- A thesis on multi-label learning for automatic annotation in March 2021
- Another PhD student defended his thesis on topic modeling in February 2023
- 24 scientific publications since 2014 in SFC, EGC, Cap, IJCNN, KDD, ICML, MDAI and IEEE TNNLSE
When it comes to Artificial Intelligence, at Lizeo we use the term “Machine Learning”. We have been developing « AI » solutions for over 10 years, both in terms of supervised approaches (i.e. requiring a labeled learning base and providing an expected output for each input) and unsupervised approaches (where the algorithm attempts to extract underlying patterns from unlabelled data).
Examples of unsupervised algorithms include :
The discovery of topics in a set of documents
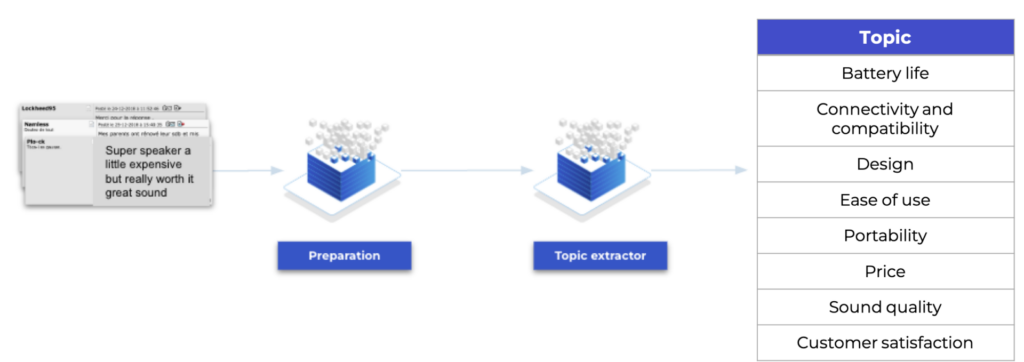
To do so, we based our work on the original Topic Modeling approach and then developed it into a specific Embedded Hierarchical Dirichlet Process (EHDP) – Palencia-Olivar et al. 2021.
The detection of outliers in a collection of price time series
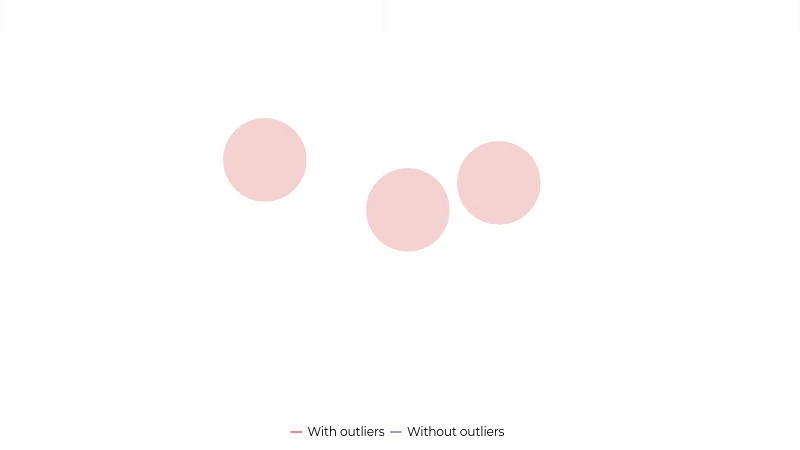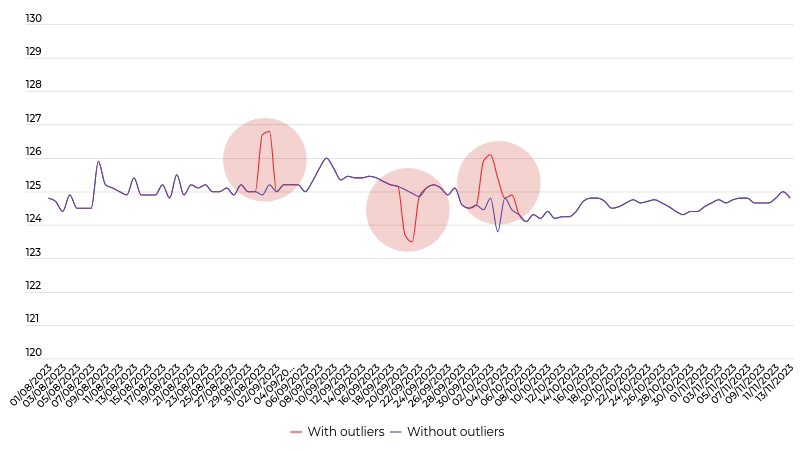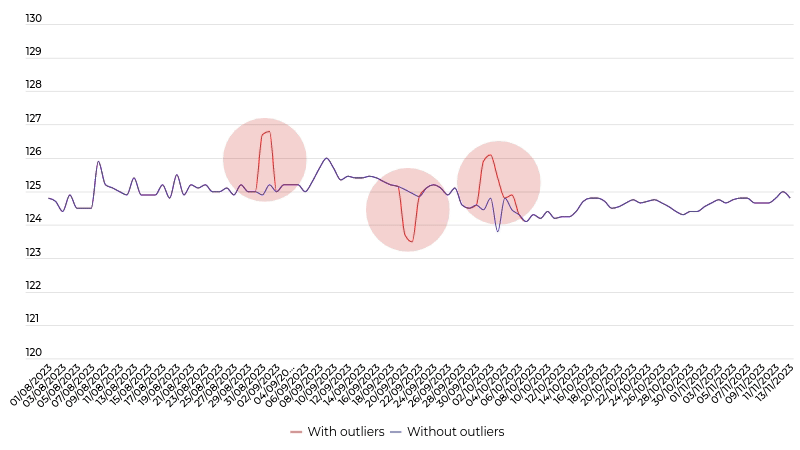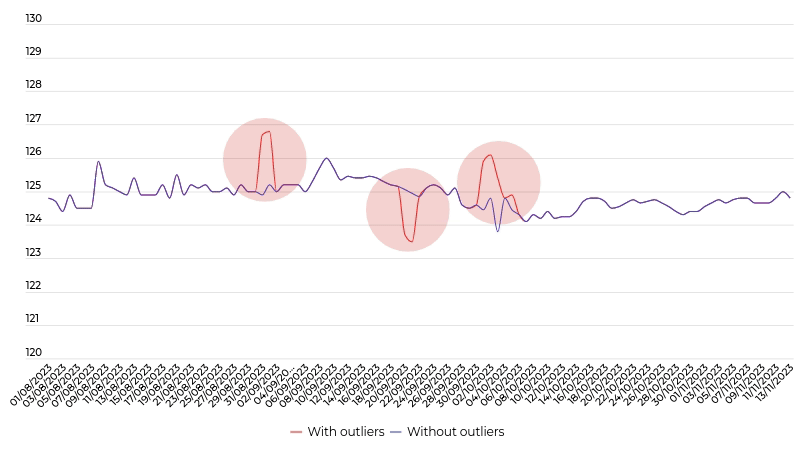
We wanted to move away from conventional approaches that would remove the points that are global outliers (the dotted line area) and not necessarily the points that are outliers in relation to other points (the solid line area). Indeed, the fact that the majority of prices for a given product are increasing is not necessarily an error. Whereas, if certain prices become locally inconsistent then this may be the real problem. To do this, we developed LADOP, which was published in the scientific journal “IEEE Transactions on Neural Networks and Learning Systems” in 2021.
Examples of supervised algorithms include:
Matching products collected from sites and a reference database
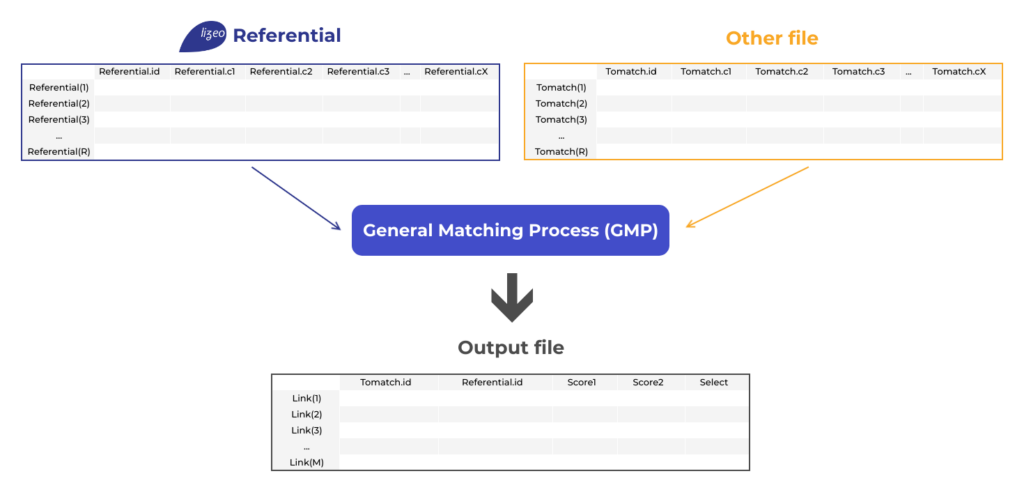
A matching process takes an input as a pair of data streams classically named “referential” and “tomatch” to be matched. The expected result is a stream containing a list of pairs (tomatch.id, referential.id) with scores and a potential selection (True or False) based on the score values.
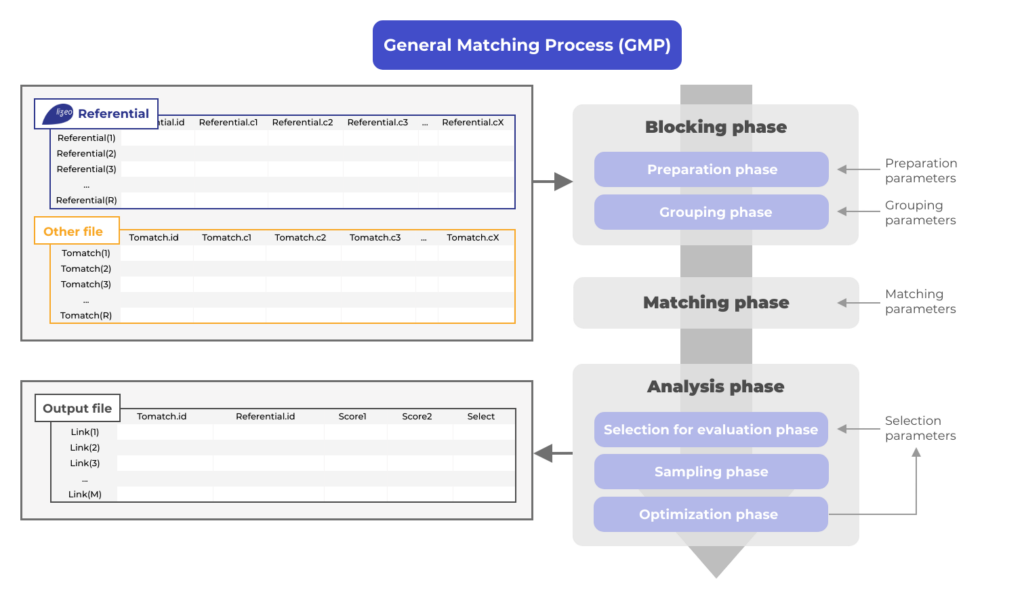
To do so, we have developed our own generalized matching algorithm, which we use on different structured data streams such as classified ads or vehicle data streams taken from websites.
Automatic qualification of user reviews
This approach requires a learning phase based on a qualified base of texts with associated topics and tones to create the models for qualification.
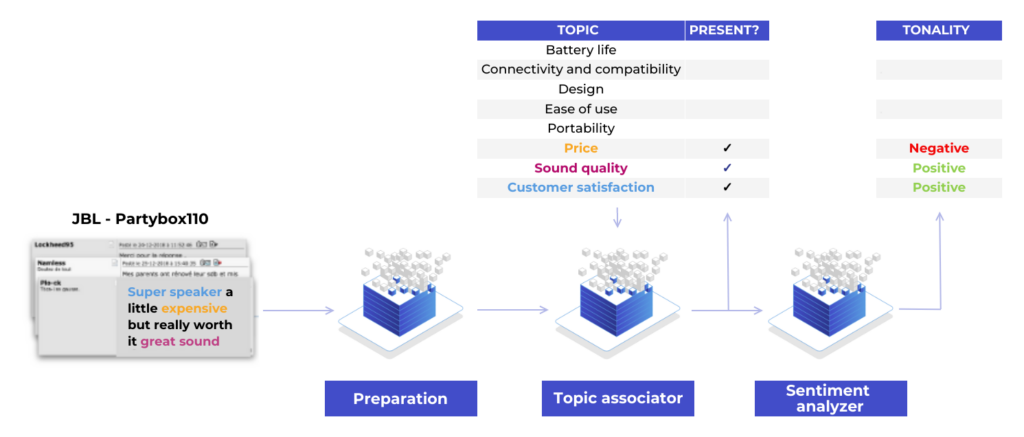
The inference phase simply uses the models learned previously to qualify a new text.
Obviously, we are not indifferent to the current explosion in very large AI language models (such as ChatGPT). We evaluate and integrate them as complimentary building blocks, but always with a scientific and critical vision.
For example, for the automatic qualification of opinions, we have compared the different versions of GPT in various fields, and the results are sometimes very surprising. For example, in the topic of tires, the results of the latest OpenAI models are twice as low as the previous model. It’s crucial to systematically test and monitor changes in models.
Machine Learning & Data Science are at the core of our R&D
ANTICIPATE MARKET CHANGES TO ADJUST YOUR STRATEGY
- Price & Market volume
- Purchasing behavior & customer profiles
- Product life cycles
DETECT AND ANALYZE CONSUMER SENTIMENT
- Named Entity (brands, products, retailers, etc.)
- Properties
- Topics
Contact us
Let’s work together to find the best approach to meet your company’s needs.